 Shin_Code
Shin_Code ども、Shinです。
Pythonの練習ということで、Twitterで自動呟きBotを作ってみました。
呟くと言っても予め自分が用意しておいた文章を一定時間置きに呟くだけです。
ということで、コードとその内容をメモ用に残しておきます。
Twitter_botのコード紹介
こんな感じでBotがツイートしてくれました↓
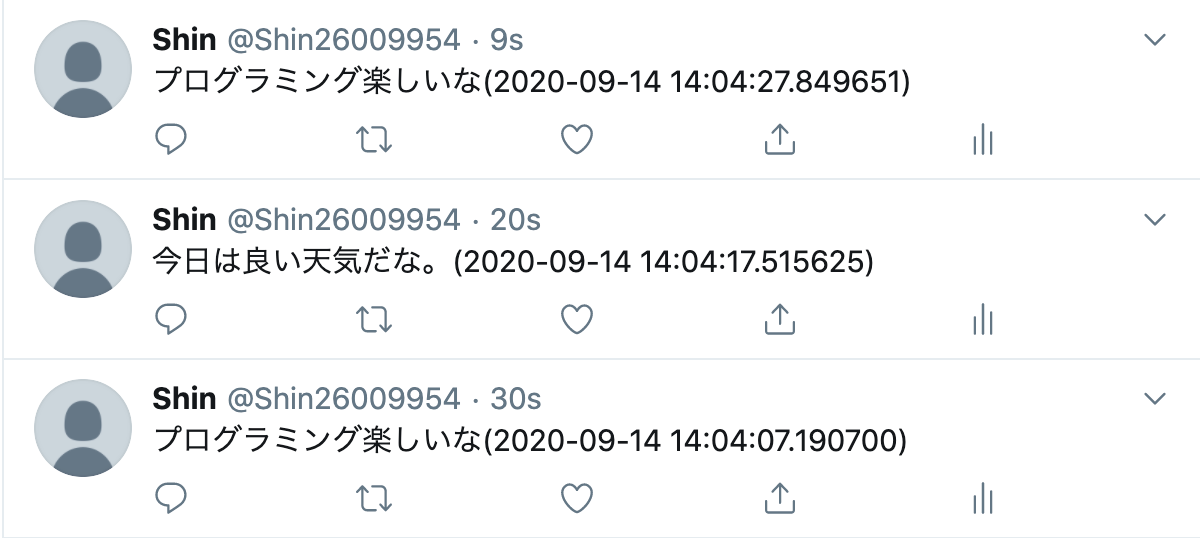
それでは、コードの説明です。2つPythonファイルがあります。
<twitter_bot.py>
import time
import text_random
# 10秒置きに自動ツイートする
while True:
time.sleep(10)
text_random.bot_text()
こちらの呟きを指示するメインファイルです。
importした「time」は時間を扱うときに使うライブラリです。
今回は「10秒置きに呟く」というスリープタイムを設けたかったので、timeライブラリをimportしました。10秒ではなく1分にしたい場合はsleep(60)でOKです。
また「text_random」は私が自作で作った関数をimportしています。このファイルについては下記をご覧ください。
<text_random.py>
import tweepy
import datetime
import random
AK = 'aaaaaaaaaaaa'
AS = 'bbbbbbbbbbb'
AT = 'cccccccccccc'
ATS = 'dddddddddddd'
auth = tweepy.OAuthHandler(AK, AS)
auth.set_access_token(AT, ATS)
twitter_api = tweepy.API(auth)
def bot_text():
text_List = ['今日は良い天気だな。', 'プログラミング楽しいな', 'Python楽しいな']
text = random.choice(text_List)
data_now = datetime.datetime.now()
twitter_api.update_status(text + '(' + str(data_now) + ')')
こちらは呟くテキストの内容を別ファイルで作ったものです。
12行目まではTwitterAPIを利用するためのテンプレですよね。API取得のためにアクセストークンやらを発行しておいてください。
「def bot_text()」の部分は文字通りツイートのテキスト内容のコーディングです。
呟きたいテキストをtext_List(リスト型)に格納しました。
そのリスト内でランダムにBotが出力してもらえるようにrandom.choice()メソッドを利用、リスト内要素をランダムにとってこれる優れもの。import randomは忘れずに。
datetimeに関しては最後に詳細を記述しておきます。
最後の
twitter_api.update_status(text + '(' + str(data_now) + ')')
は、リスト内からランダムに文章を選んだもの(text)と呟く時の時間をツイートするコードです。
テキストを出力するときはStr型であることに注意ですね。最初に(text + data_now)としてしまったのでエラー吐いてましたが、エラー分で気づくことができました。
エラー文やらインデントを丁寧に教えてくれるのがPycharmの魅力だと感じました。
datatimeについて少し解説
ぶっちゃけツイート文に日時は必要ないと思った人がいると思います。
が、この日時ツイートがないと重複した文章と見做されてしまってエラー吐かれるんですよね。
「’code’: 187, ‘message’: ‘Status is a duplicate.」
duplicateというのは「重複した」的な意味があるので、同じ文章をそのまま連続してTwitterに投稿するとエラーするという意味になります。
これは私にも以前、経験したことがあります。これはTwitter社が設定したルールなので従うしかないでしょう。
Bot作りの所感
Pythonの練習とTwitterAPIに興味があったので挑戦してみた。
API取得までが大変だったが、いざコードを書いてみると案外簡単だったので驚いた。
自分でもBotが作れることで少し自信をつけることができた。
また、Udemyで習ったPythonのコーディングを少し活かせた気がする。
例えば、今回は2つファイルを用意してなるべく可読性のあるコード作りに努めた。ファイル名や関数名を一眼みて分かるように設定したり、工夫をした。
おかげでメインファイルのコーディングがかなり少ないことが分かるだろう。関数をインポートするだけが理想のコーディングと感じた。
分からないことももちろんあったが、その都度、欲しい機能をググっては実験を繰り返してなんとか出力できたので嬉しかった。
次にやりたいこと
TwitterAPIを触ってみた感じ、まだまだいろんなことができそうだ。
例えば「検索キーワードのトレンドワードを抽出」したり「ファボが多い順にデータを取り出す」などPandasを用いてデータとして残すことができそう。
Pandasの取り扱いが未熟なので、次APIを触る時は挑戦してみてもよさそう。
執筆時間1h